
Aligning Audio Encoder and LLM via Preference Fine Tuning.
Completed:
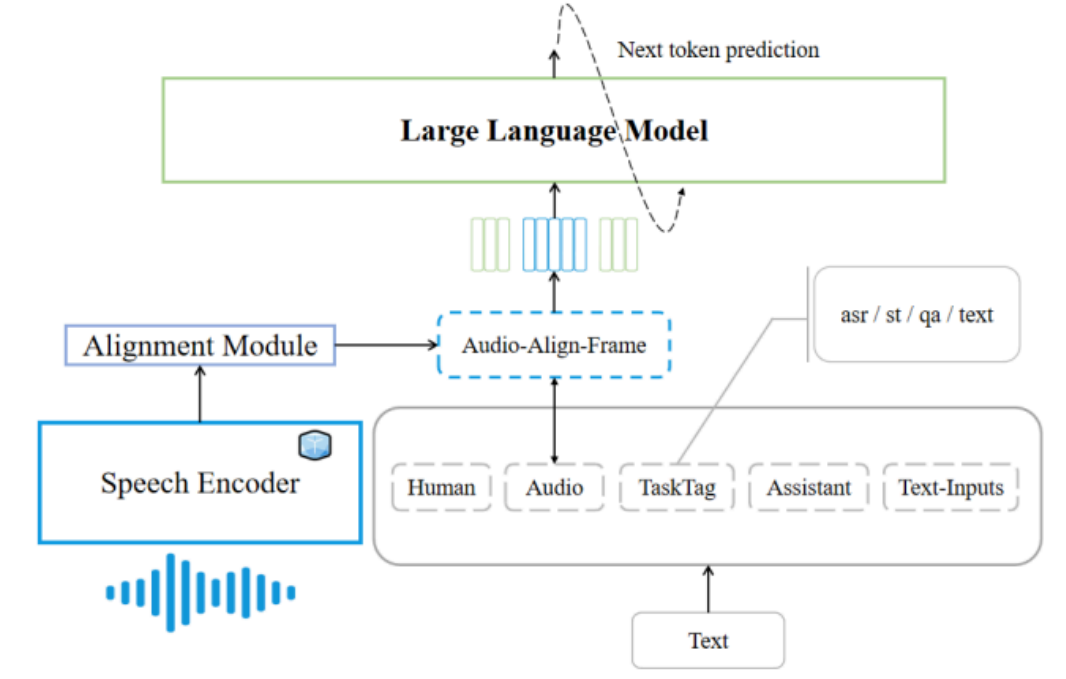
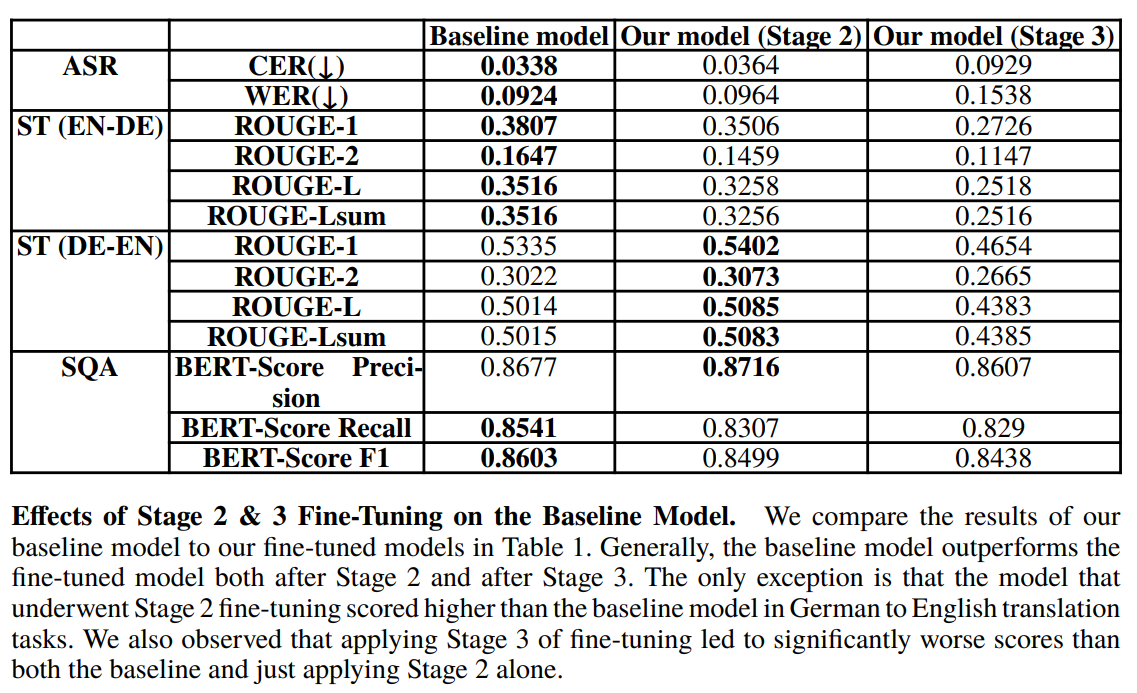
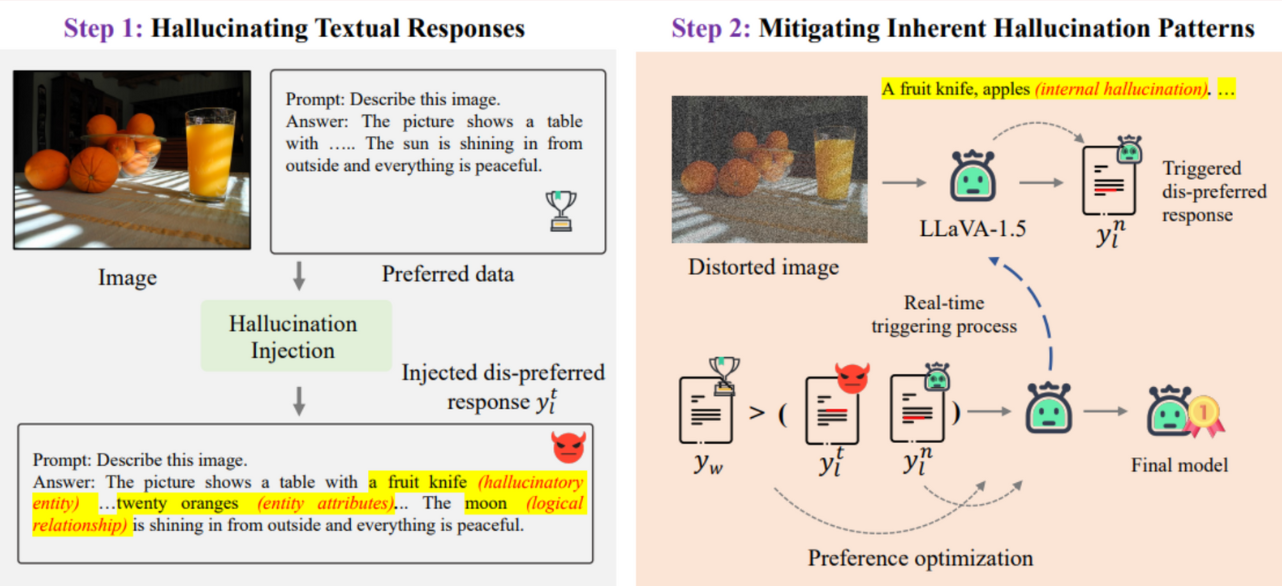
.The project focuses on enhancing speech-to-text alignment by combining audio encoding with large language models (LLMs) using preference fine-tuning. Building upon previously established state-of-the-art frameworks, this work employs the POVID method, adapted as PROVID (Preference Refinement for Optimized Voice-to-text Inference and Decoding). The approach integrates OpenAI's Whisper encoder with a linear alignment module and Meta's Llama-3.2 11B-Instruct model. By generating dispreferred speech data through hallucination injection, the system refines audio-to-text alignment across tasks like automatic speech recognition (ASR), speech translation (ST), and speech question answering (SQA). Though the results show mixed improvements, particularly in German-to-English translation, the research highlights scalable alignment methods and the potential for further refinement in multimodal applications.
Check out the official PDF for Aligning Audio Encoder and LLM via Preference Fine Tuning.
⚪ This project is the result of a semester project completed in Fall 2024 for the University of Central Florida. See the university website here.
⚪ This project calls on research in LLM multimodal alignment. Check out the references:
[1] Y. Zhou, C. Cui, R. Rafailov, C. Finn, and H. Yao, “Aligning Modalities in Vision Large Language Models via Preference Fine-tuning,” arXiv preprint arXiv:2402.11411, 2024.
[2] B. Wu, C. Yan, and H. Pu, “Transferable Speech-to-Text Large Language Model Alignment Module,” arXiv preprint arXiv:2406.13357, 2024.
▱▰▱ Project Goals. ▰▱▰
- 1. Extend the POVID method, originally designed for vision-text alignment, to align audio encoders with LLMs for speech-to-text tasks.
- 2. Create hallucinatory speech data using the Llama-3.2 11B-Instruct model to avoid the need for human-annotated data, enabling scalable and efficient alignment fine-tuning.
- 3. Optimize model alignment to enhance performance in Automatic Speech Recognition (ASR), Speech Translation (ST), and Speech Question Answering (SQA) tasks.
- 4. Assess how effectively the POVID framework can be applied to audio-text modalities and measure its impact on alignment quality.
- 5. Explore different stages of fine-tuning, data sizes, and noise-injection methods to identify the most effective strategies for improving speech-to-text alignment.